


In my last post, A Simple MassTransit Publish/Subscribe Example, we looked at how to build basic publishers and subscribers using MassTransit and RabbitMQ. In the example, however, we were only using a single RabbitMQ instance on a single machine. In the real world, your publishers are most likely to live on separate machines from your subscribers. To do that, we need to set up a RabbitMQ cluster.
RabbitMQ Clustering
A RabbitMQ cluster (or broker) can consist of multiple nodes, each running an instance of the RabbitMQ application. All of the nodes will share configuration information, such as users, exchanges, and queues. Recall from our last discussion that an exchange is like a post office and a queue is like an actual mailbox containing the resting place of messages. The actual queue, or mailbox, only lives on the node where the queue was created, but the knowledge of the queue’s existence is shared by the cluster, as is the full routing information contained in the exchanges. (Note that queues can be replicated for high-availability requirements, which we may cover in a future post.)
A Common Clustering Pattern
A pattern I like to use for clustering RabbitMQ nodes is to have a node live on each machine that participates in the overall application. For example, I will install instances of RabbitMQ on each web server that makes up a web application and will be publishing messages related to the application. Then, I will install an instance of RabbitMQ on each machine that will be running a service that will subscribe to the messages. The diagram below illustrates this pattern.
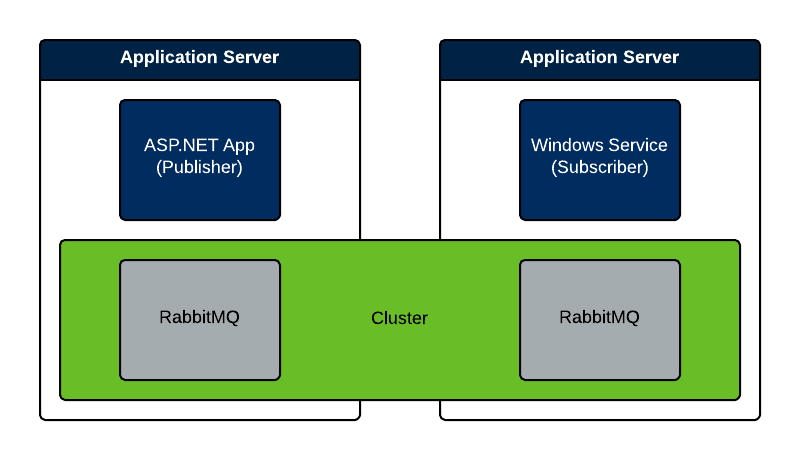
Setting Up the Cluster
For the purposes of this example, we are going to assume you have two Windows machines (virtual or otherwise) named Publisher and Subscriber. Install RabbitMQ on each of these machines, referring to the installation instructions in my previous blog post.
Erlang Cookie
The first thing that needs to be done is to set up the Erlang cookie on each machine so that the cookies are the same. (Remember, RabbitMQ is an Erlang application.) ASP.NET developers may be familiar with the concept of creating a common Machine Key for a cluster of web servers. The Erlang cookie is a corollary to this process. It is a key that indicates that the multiple Erlang nodes can communicate with each other. All the nodes in a RabbitMQ cluster must have the same Erlang cookie.
When installing Erlang on Windows and installing RabbitMQ as a Windows Service, the Erlang cookie is placed in two locations – C:\Users\Current User and C:\Windows. The RabbitMQ clustering guide recommends making sure all of the cookies on the machine are the same. Copy the cookie from C:\Windows on the Publisher machine to C:\Users\Current User on the same machine and then to both C:\Users\Current User and C:\Windows on the Subscriber machine. All four cookies should have identical content (you can inspect with Notepad to be sure).
Restart the RabbitMQ service on both machines.
Final Cluster Setup
If you’ve got the Windows Firewall turned on, be sure to allow incoming TCP traffic on ports 4369 and 25672 on both the Publisher and Subscriber machines.
Now, from the Subscriber machine, open up the “RabbitMQ Command Prompt (sbin dir)” item (added by the RabbitMQ installer). Run the following commands:
> rabbitmqctl stop_app > rabbitmqctl join_cluster rabbit@Publisher
What we are doing here is telling the instance of RabbitMQ running on the Subscriber machine that we want to join a cluster that is hosted by the Publisher machine (which is currently a cluster of one). Restart the RabbitMQ Windows service after running this command.
Inspecting Your Cluster
Now, on either the Publisher or the Subscriber, open the web-based management console at http://localhost:15672/. (Recall from our previous post that the web-based management console is a plugin we need to install.) On the first page, you will see the details of our newly created, multi-node cluster!
MassTransit in Action
Now let’s put our cluster to the test. Build the sample applications that we created in the previous post. Copy the contents of TestPublisher\bin\Debug to a folder on the Publisher. Likewise, copy the contents of TestSubscriber\bin\Debug to a folder on the Subscriber.
Launch TestSubscriber.exe on the Subscriber machine first. Then, launch TestPublisher on the Publisher machine. Finally, send a message from the Publisher, and watch it appear on the Subscriber.
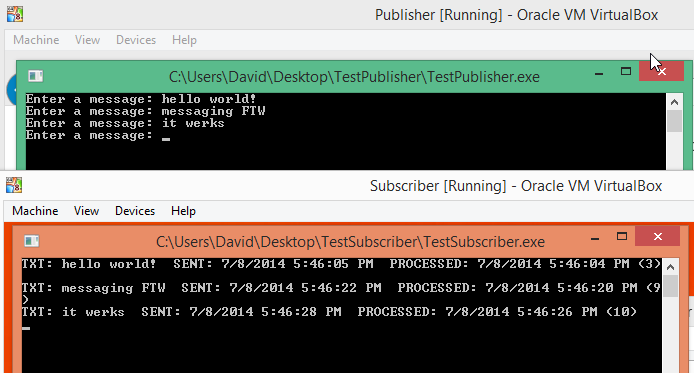
Notice how we didn’t have to modify any code in the sample application? This is because we set up the code to connect to RabbitMQ on localhost. Because each local instance of RabbitMQ on the two machines was part of a single cluster, they shared information about the exchanges and queues necessary to make the MassTransit service bus work its magic, as if there were only a single RabbitMQ instance!
What’s Next?
Next up, we’ll take a look at scaling this up to a real-world example. We’ll create an ASP.NET web application that can publish messages and a custom Windows service that can be our subscriber of the messages. Down the road, we’ll look at having multiple subscribers for the same message type in two different patterns: one for scaling out message processing and another for having different processing occur in separate Windows services.
As always, please send your suggestions for things you’d like to learn how to do with MassTransit.
Happy to be the first to comment here. Great post. Well explained and clearly thought out. Bookmarking.
Two great posts so far, keep up the excellent writing!
Also, I’d be happy to explain how HA queues come into play if you want to post about that. In our case, we prefix every queue that needs to be HA with the “ha-” prefix, and then use a cluster policy to set HA on any queue that matches the name. Makes it easy to opt-in to high-availability (mirroring of queue content) queues.
Thanks Chris and John! Appreciate the words of encouragement!
David, your blog post outlines a method for setting up a RabbitMQ cluster. In a PROD environment with, let’s say, 50 web servers and 10 back-end processing servers, we’d be talking about a RabbitMQ cluster with 60 nodes, correct? Do people actually do that in the real world?
I don’t know, honestly. It does not seem likely to me. I did a little research and couldn’t find examples of anyone doing an actual RabbitMQ cluster that big. You may be better off (or at least in the majority) with more of a centralized broker setup. Create a cluster of 2 or 3 RabbitMQ machines and put them behind a load-balancer or heartbeat/keepalive virtual IP for HA.
MSMQ deployments definitely do reach that scale and beyond, but that’s because they don’t have to share any state, so they aren’t replicating any data back and forth. You need a separate database of some kind to keep track of subscriptions.
In our scenario that is that big, we have 4 centralized brokers as state by Andrew, that are in cluster+HA(+sharding work in progress).
Fantastic series! I really appreciate you starting small, but then scaling up to real-world examples.
For monitoring RabbitMQ (example: I need our technical operations support team to be notified if RabbitMQ goes down), have you ever integrated it with something like SCOM (Microsoft System Center Operations Manager)?
I haven’t used it with SCOM, no. Take a look (if you haven’t already) at my post on Monitoring RabbitMQ: http://looselycoupledlabs.com/2014/08/monitoring-rabbitmq/
The basic pattern for integrating with any monitoring system would be to write a command line tool with C# (or PowerShell if you prefer) that extracts the metrics you are looking for (and of course, if it can’t connect at all, that’s a server down scenario) and then write the appropriate script to get that info into your monitoring tool. (For Nagios, I use the NSCA client to send passive checks into Nagios.)
So far, some googling hasn’t produced a completed example solution for monitoring RabbitMQ from SCOM. There’s people doing it, just no canned solutions available. Maybe you could be the first!
Good luck.
Hey David. Thanks for such a great tutorial.
Actually i have create a setup according to your tutorial.
Here is my structure:-
-Two virtual web servers acting as publishers (using load balancing)
-Two virtual clustered servers acting as subscribers
-One virtual server to handle subscribers subscriptions (name: Submaster)
I have installed RabbitMq server on both web servers and Submaster.
Other two clustered virtual servers are using queue (rabbitmq://Submaster/Subscriber) from Submaster.
When i inspect my consumer, it is getting the request but throwing exception when responding.
Here is exception:-
——————————————————————————————————
2015-01-11 19:34:21,280 [4] ERROR MassTransit.Context.ServiceBusReceiveContext [
(null)] – ‘System.Action`1[[MassTransit.IConsumeContext, MassTransit, Version=2.
9.0.0, Culture=neutral, PublicKeyToken=b8e0e9f2f1e657fa]]’ threw an exception co
nsuming message ‘MassTransit.Context.ReceiveContext’
MassTransit.Exceptions.SendException: rabbitmq://localhost/SAPTCO.WebWare1 => An
exception was thrown during Send —> RabbitMQ.Client.Exceptions.BrokerUnreacha
bleException: None of the specified endpoints were reachable —> RabbitMQ.Clien
t.Exceptions.ConnectFailureException: Connection failed —> System.Net.Sockets.
SocketException: No connection could be made because the target machine actively
refused it 127.0.0.1:5672
According the exception text, your Send is trying to go to rabbitmq://localhost/SAPTCO.WebWare1
Dear i need your guidance.
Actually i have already explained my structure. Please tell me i am wrong anyware.
-Two virtual web servers acting as publishers (using load balancing)
-Two virtual clustered servers acting as subscribers
-One virtual server to handle subscribers subscriptions (Submaster)
-Two web servers and One virtual server (Submaster) are clustered through RabbitMQ.
I have installed RabbitMq server on both web servers and Submaster and clustered them.
Do i need to install RabbitMq server on other two virtual servers or should i use the Submaster clustered queue?
Because you are using the competing consumer pattern you must connect to the submaster machine for receiving messages. Otherwise, you risk processing duplicate messages. You can also use submaster to send messages as that keeps the configuration simpler.
So as per my understanding i will not install RabbitMq server on both subscriber servers, and i will only initialize MassTransit on both machines and connect to Submaster to receive messages.
At first i did the same, both Subscriber machines are receiving the messages, but when i try to respond to context than it is throwing the exception as i mentioned earlier.
Probably it is trying to accesses the publisher rabbitmq://localhost/SAPTCO.WebWare1.
By the way when i connected to submaster and receiving messages, shall i respond directly to WebWare1 (Publisher)?
I haven’t sent replies back to web applications. I would think, however, you would still want to use submaster to send the replies. Since all your rabbitmq servers are part of the same cluster, it will know how to route the messages (and hold onto them if the web server is down).
Yeah actually problem lies here. When i respond to context, context has EndPoint URI of rabbitmq://localhost/SAPTCO.WebWare1. That is why it is throwing the exception.
But if i install rabbitmq server on my both Virtual Servers with using same queue of SubMaster, it is responding back. But is it right mechanism?
No, I don’t think so, but it’s hard to know without seeing your code. You don’t want your consumers to be connecting to different instances of RabbitMQ because they will pull duplicate messages off the queue. Can you just change the endpoint for your reply message?
Actually there are real time transactions. I have developed a booking system. When request comes for trips search, i have to send response real time and to the same request. Any idea how can i send response out of message context?
I have not done that, no. You might try the MassTransit mailing list. https://groups.google.com/forum/#!forum/masstransit-discuss
thanks David. I achieved it by downgrading MT to 2.6.5 and implemented distributor using MSMQ, distributor doesn’t work on latest MT build.
Great series! Kudos and keep up the great writing.
What would be your recommendation in the scenario can both consume and publish messages. Also, there can be, let’s say 5 applications that participate in the process, each consumes from one queue, processes and then publishes back to an exchange with a different queue? So each application acts as a consumer as well as publisher.
My thought is that you can have a webserver running all the applications, and all talking to one RabbitMQ instance. Scale out this setup to other webservers and each webserver has its own dedicated RabbitMQ instance. All RMQ instances would be clustered. Mostly like the setup you mentioned above, the only difference being both the publisher and subscriber would have the same RMQ instance that they would talk to from one webserver, unless any RMQ instance goes down and in that case, the applications would throw “Send exception” while consuming or publishing. The exception should not be a problem as other webservers would continue to process the messages, since its a clustered RMQ environment.
Or would you prefer having a load balancer in between the webservers and RMQ cluster instead?